Architecture
Overview
While each and every specific supercomputer looks different there are some common features that can be described.
In general, such a system is composed of several individual computers which are called nodes. Several nodes are combined inside a rack.
Quite often, the cooling and networking is done within the racks. I.e., for cooling this is either (warm) water cooling that runs through each node or to one of the doors and the heat from the nodes spread via normal fans. For the network we have a switch in each rack that connects to the nodes.
In general we try to have a homogeneous architecture, i.e. homogeneous nodes in one rack.
Nowadays, with the use of accelerator cards (GPUs or FPGAs) we quite often see that several racks form a partition. Where inside the partition the nodes all look the same, are located near each other, and are interconnected with high speed.

Finally, several partitions will form the computing part of the high performance system, but some additional components are required.
This includes various high performance parallel storage systems for different usage (home, scratch, ...), the high speed netword (switches, routers, and so forth), login nodes, monitoring systems, and more.

Real world examples
Leonardo (#4 on the TOP500) has a nice animated video that shows the different sections nicely:
For Lumi the layout looks like the following.
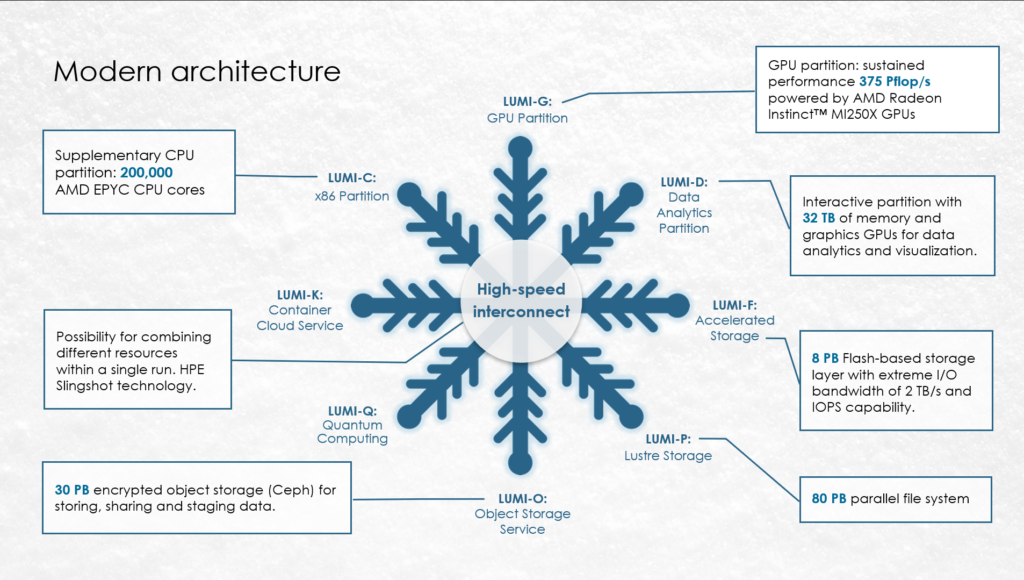
Reasons and consequences
The main idea of a HPC System is to maximize performance of a computation [1]. This is strongly reflected in the architecture described above.
For the following discussion of the components, we assume that we start with a computation on a single core and spread it out over the entire system. This allows us to discuss the different parts that help to make the computation as fast as possible. While this will probably be some weather simulation or the collision of two galaxies it could also just be the computation of .
Node
In the previous sections, we have seen how to move the computation from a single core within one CPU to multiple cores. Obviously, the faster the CPU the faster the computation. Usually a node will have multiple CPUs so with a bit of extra work we can make sure that all of them are used as well. Now there is going to be a bit of communication between the CPUs so the faster they are connected the better. Nevertheless, we will try to write our code such that communication between the two different CPUs is minimized (locality). The more we know about the architecture and the particular components of the node the better we can optimize our code and soon the node is running at 100% peak performance. Now we spread out to the next nodes in the rack.
Rack
This is not too hard, as they look exactly the same and are (physically) close. Of course, there is some overhead with the code, we need to communicate between the nodes but luckily there is a fast connection. Again, we will try to write our code such that the communication between the nodes is minimized. Soon the entire rack is again working at peak load. Thus we pull more racks in and form a partition.
Partition
Since one partition usually consists of identical racks, we just need to make sure that we localize communication again.
The main idea of partitions is to have some differences in the hardware. So maybe the neighboring partition has GPUs (probably 2 to 4 per node). Luckily, we know how to includes GPUs in our computation. Maybe there is even one part of our computation that is super fast on GPUs but not so fast on CPUs, so we move this part to the GPU section while the CPU is running CPU optimized code. Again communication is needed so lets consider the high speed interconnect.
High Speed Interconnect
We could simple wire up the nodes with normal ethernet cables or if we are insane try WiFi. This works fine, if we do not have a lot of data that gets send around. It is the same as with the internet connection at home, if we watch two 4K video streams, download the latest data bundles for our new cool project we will see that performance goes down.
This is basically the reason for the high speed interconnect. Mostly glass fiber connections with special dedicated hardware are used. Naturally, having multiple ports is essential in case one fails. Each node is connected to others via two different routes to ensure that communication is always possible. The faster this system is the faster our computation will be, and again, if we know how it looks we can optimize for it.
Speaking of data transfer, we probably also need to store and load data from disks. So lets look at the storage.
Storage
Providing storage in such a system is not an easy feat. We want to make sure that each node can access all the data it needs and we also want to make sure that several nodes can access data at the same time, while no user should be able to access data from somebody else (sensitive data, or data with licenses). This is why there is a parallel filesystem in place. The different layers and spaces are easily explained from their use.
Each node will have a SSD for the operating system and the basic programs needed, maybe you can also use this for temporary storage during computations.
Next each user should have a home directory where the most important part of the project is stored and we need this available all the time on all the nodes, but this directory can be rather small.
Usually, we will also have something called scratch where data is stored as a result of computations or from (program) steps. With regard to Julia this could also be the packages used. Nevertheless, this should be large but we should assume that this memory is volatile and there is no backup. Some systems will offer an archive or something similar for long term storage.
Entire HPC System
A supercomputer, as the name suggests, is at its core a scaled up version of a normal CPU/GPU/computer. At the end, it even works similar, we will see how to interact with one a bit later.
What we skipped above when we moved from one node to an entire rack was access. Now accessing multiple computers from our program is not trivial but also not magic. In order to make it not unnecessarily hard and therefore fast a HPC system is build such that his access is easy, you will have the same user with the same data and rights. Basically the system is build as a trusted space. Once you are in you can move around freely. Of course this will also mean you need to be careful not to get in the way of others but the way you run programs on such a system helps to keep it manageable. As always, the idea behind it is that the entire purpose of the system is to generate as much performance as possible so this is a risk worth taking.
First, the key to utilizing the maximal performance of a system is to know how it is build. As we have seen in the previous section, the more we know about the system the better we can optimize our code.
Second, all design choices are made with code performance in mind. As a consequence, some tasks are cumbersome for users but they are always improved.
| [1] | There is a large discussion if this is the correct metric and maybe the overall time, including the user waiting to run something should be included but we leave that for later. |